|
|
认识 AudioGPT:一个连接 ChatGPT 和音频基础模型的多模态 AI 系统
AI 社区现在受到大型语言模型的显着影响,ChatGPT 和 GPT-4 的引入具有先进的自然语言处理能力。得益于庞大的网络文本数据和强大的架构,可以像人类一样阅读、写作和交谈。尽管在文本处理和生成方面取得了成功的应用,但音频模式、音乐、声音和说话头的成功是有限的,尽管它非常有利,因为:1)在现实世界中,人类每天都使用口头语言进行交流对话,他们使用语音助手让生活更方便;2)需要处理音频模态信息才能实现人工生成成功。
ChatGPT 迈向更复杂的人工智能系统的关键一步是理解和产生声音、音乐、声音和说话的头像。尽管音频模态有很多优势,但由于以下问题,训练支持音频处理的 LLM 仍然很困难:1)数据:很少有源提供真实世界的口语对话,获得人工标记的语音数据既昂贵又费时-消耗操作。此外,与庞大的网络文本数据语料库相比,需要多语言会话语音数据,而且数据量有限。2) 计算资源:从头开始训练多模式 LLM 需要大量计算且耗时。
来自浙江大学、北京大学、卡内基梅隆大学和中国人民大学的研究人员在这项工作中展示了“AudioGPT”,这是一个在理解和产生口语对话中的音频模态方面表现出色的系统。尤其:
他们使用各种音频基础模型来处理复杂的音频信息,而不是从头开始训练多模态 LLM。
他们将 LLM 与语音对话的输入/输出接口连接起来,而不是训练口语模型。
他们使用 LLM 作为通用接口,使 AudioGPT 能够解决众多音频理解和生成任务。
从头开始训练是没有用的,因为音频基础模型已经可以理解并产生语音、音乐、声音和会说话的头像。
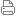
使用输入/输出接口、ChatGPT 和口语,LLM 可以通过将语音转换为文本来更有效地进行交流。ChatGPT 使用对话引擎和提示管理器来确定用户在处理音频数据时的意图。AudioGPT 过程可以分为四个部分,如图 1 所示:
• 模态转换:使用输入/输出接口、ChatGPT 和口语 LLM 可以通过将语音转换为文本来更有效地进行交流。
• 任务分析:ChatGPT 使用对话引擎和提示管理器来确定用户在处理音频数据时的意图。
• 分配模型:ChatGPT 在接收到韵律、音色和语言控制的结构化参数后分配用于理解和生成的音频基础模型。
• 响应设计:在音频基础模型执行后生成并为消费者提供最终答案。

图 1: AudioGPT 概览。模态转换、任务分析、模型分配和响应生成是构成 AudioGPT 的四个过程。为了处理困难的音频工作,它为 ChatGPT 提供了音频基础模型。此外,它连接到模态转换接口以实现语音通信。他们制定了设计指南来评估多模式 LLM 的一致性、容量和稳健性。
评估多模式 LLM 在理解人类意图和协调各种基础模型协作方面的有效性正成为一个越来越受欢迎的研究问题。实验结果表明,AudioGPT 可以为不同的 AI 应用程序处理多轮对话中的复杂音频数据,包括创建和理解语音、音乐、声音和说话的头像。他们描述了本研究中 AudioGPT 的一致性、容量和稳健性的设计概念和评估程序。
他们建议使用 AudioGPT,它为 ChatGPT 提供了用于复杂音频工作的音频基础模型。
这是该论文的主要贡献之一。模态转换接口作为通用接口与 ChatGPT 耦合,以实现语音通信。他们描述了多模式 LLM 的设计概念和评估程序,并评估了 AudioGPT 的一致性、容量和稳健性。AudioGPT 通过多轮讨论有效地理解和制作音频,使人们能够以前所未有的简单性制作出丰富多样的音频材料。代码已在 GitHub 上开源。
出处:https://www.marktechpost.com/202 ... -foundation-models/ |
|







 发表于 2023-5-3 19:27:35
发表于 2023-5-3 19:27:35
 QQ好友和群
QQ好友和群 收藏
收藏 转播
转播 分享
分享 顶
顶 踩
踩